주식투자분석을 위하여 신문기사나 소셜네트웍에서 발생하는 사건이나 기업에 대한 긍정,부정인식이
다음날의 주가에 영향을 미친다고 가정한다면, 텍스트를 해석하여 감정수준을 알아내는 것은 중요한 일입니다.
본 글에서는 해외 과학자가 기고한 글의 한글판을 공유하여 이러한 기술을 나누고자 합니다.
우리나라 시장과 한국환경에 맞는 ML처리도 적용해볼 생각입니다.
TextBlob 소개
텍스트 데이터 처리를 위한 Python 라이브러리, NLP 프레임워크, 감정 분석
Python용 NLP 라이브러리인 TextBlob 은 품사 태깅 및 감정 분석 과 같은 많은 좋은 점을 듣고 한 번 시도하기로 결정했기 때문에 이번이 처음입니다. TextBlob 을 사용하여 자연어 처리 작업을 수행하고 있습니다.
Yelp 데이터 세트 는 개인, 교육 및 학술 목적으로 사용하기 위한 비즈니스, 리뷰 및 사용자 데이터의 하위 집합입니다. JSON 파일로 제공되며 여기yelp_academic_dataset_review.json 에서만 및 yelp_academic_dataset_user.json및 다운로드할 수 있습니다 .
자료
데이터 세트는 JSON 형식이며 pandas 데이터 프레임에서 읽을 수 있도록 먼저 JSON 데이터를 로드한 다음 반구조화된 JSON 데이터를 플랫 테이블로 정규화한 다음 to_parquet테이블을 이진 쪽모이 세공 형식으로 작성하는 데 사용합니다. 나중에 필요할 때 파일 경로에서 쪽모이 세공 개체를 로드하여 pandas 데이터 프레임을 반환합니다.
다음 프로세스는 사용자 및 검토라는 두 개의 데이터 테이블을 제공합니다.
JSON_parquet.py

사용자 테이블
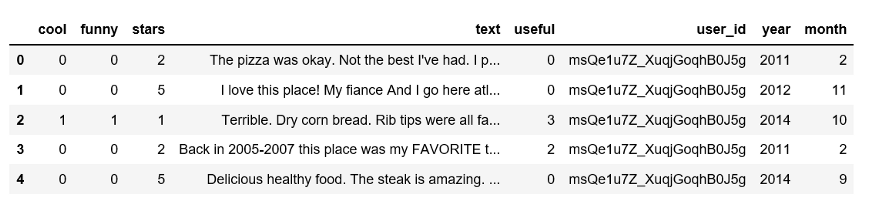
리뷰 테이블
사용자 테이블과 검토 테이블을 병합하고 접미사를 사용하여 동일한 열 이름을 처리하고 별표 0개를 제거합니다.
user_review = (review.merge(사용자, on='user_id', 방법='왼쪽', 접미사=['', '_user']).drop('user_id', 축=1))user_review = user_review[사용자_리뷰.별 > 0]별점 분포
x=user_review['stars'].value_counts()
x=x.sort_index()
plt.figure(figsize=(10,6))
ax= sns.barplot(x.index, x.values, alpha=0.8)
plt .title ("별 등급 분포")
plt.ylabel('count')
plt.xlabel('별 등급')
rects = ax.patches
labels = x.values
for rect, label in zip(rects, labels):
height = rect.get_height()
ax.text(rect.get_x() + rect.get_width()/2, 높이 + 5, 레이블, ha='center', va='bottom')
plt.show();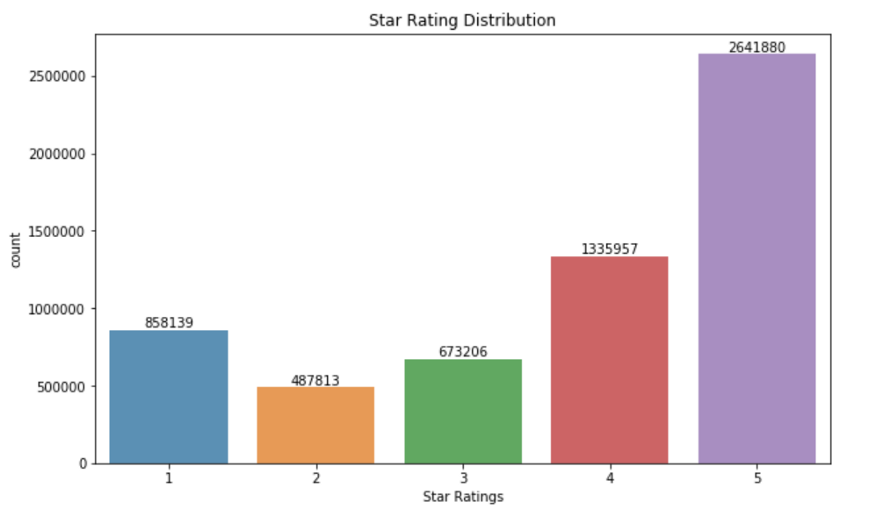
그림 1
대부분의 리뷰 별점 등급이 꽤 높고 끔찍한 리뷰가 많지 않다는 것을 아는 것이 좋습니다. 분명한 것은 비즈니스가 가능한 한 많은 좋은 리뷰를 요청하도록 유도하는 인센티브가 있다는 것입니다.
연간 리뷰 vs. 연간 별점
그림, 축 = plt.subplots(ncols=2, figsize=(14, 4))
user_review.year.value_counts().sort_index().plot.bar(title='연간 리뷰', ax=axes[0] );
sns.lineplot(x='연도', y='별', data=user_review, ax=axes[1])
axes[1].set_title('연간 별');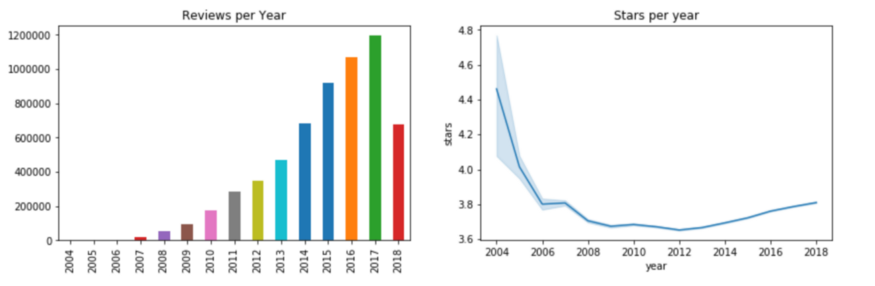
그림 2
user_review.member_yrs.value_counts()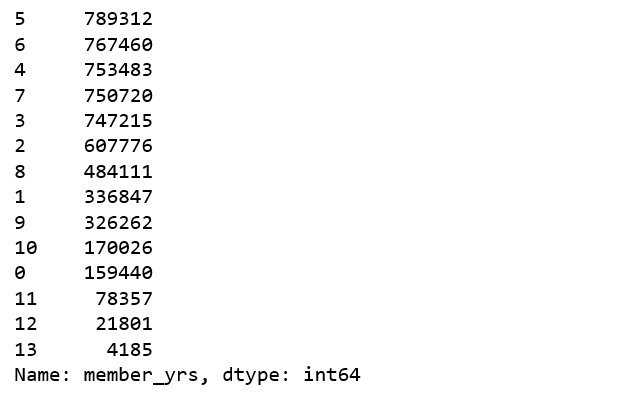
그림 3
Yelp는 2004년에 설립되었으며 그 이후로 4,000명 이상의 사람들이 Yelp 회원이었습니다.
샘플 리뷰를 살펴보겠습니다.
review_sample = user_review.text.sample(1).iloc[0]
인쇄(review_sample)
이 샘플 리뷰의 극성을 확인합시다. 극성의 범위는 -1(가장 음수)에서 1(가장 양수)까지입니다.
TextBlob(review_sample).감정
위의 리뷰는 극성이 약 -0.06으로 약간 부정적이며 주관성이 약 0.56으로 상당히 주관적입니다.
더 빠르게 진행하기 위해 현재 데이터에서 100만 개의 리뷰를 샘플링하고 극성에 대한 새 열을 추가합니다.
sample_reviews = user_review[['별', '텍스트']].sample(1000000)def detect_polarity(텍스트):
TextBlob(텍스트).sentiment.polarity를 반환합니다 .sample_reviews['polarity'] = sample_reviews.text.apply(detect_polarity)
sample_reviews.head()
그림 4
처음 몇 행은 좋아 보이고, 별과 극성은 서로 일치합니다. 즉, 별이 높을수록 극성이 높아야 합니다.
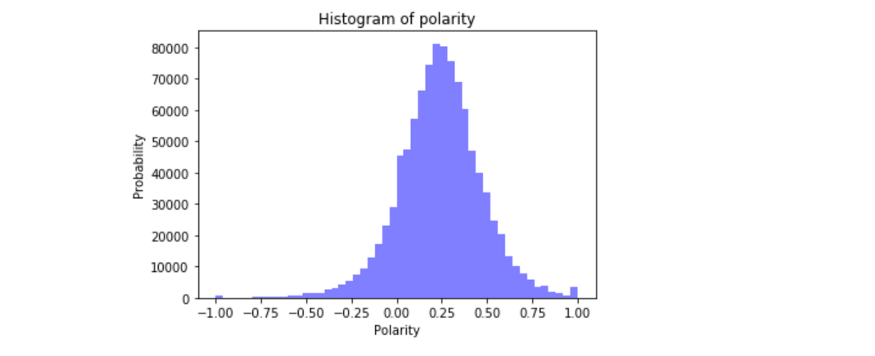
극성 분포
num_bins = 50
plt.figure(figsize=(10,6))
n, bins, patches = plt.hist(sample_reviews.polarity, num_bins, facecolor='blue', alpha=0.5)
plt.xlabel('Polarity')
plt .ylabel('개수')
plt.title('극성의 히스토그램')
plt.show();
그림 5
대부분의 극성 점수는 0 이상입니다. 즉, 대부분의 리뷰가 데이터에서 긍정적인 정서임을 의미합니다. 이는 이전에 발견한 별점 분포와 일치합니다.
별별로 그룹화된 극성
plt.figure(figsize=(10,6))
sns.boxenplot(x='별', y='극성', data=sample_reviews)
plt.show();
그림 6
일반적으로 이것은 우리가 기대하는 것만큼 좋습니다. 더 깊이 조사하고 흥미로운 점이나 특이점을 찾을 수 있는지 알아봅시다.
극성이 가장 낮은 리뷰 :
sample_reviews[sample_reviews.polarity == -1].text.head()
별점 등급이 가장 낮은 리뷰:
sample_reviews[sample_reviews.stars == 1].text.head()
그들은 부정적인 리뷰가 무엇인지 예상대로 모두 보입니다.
극성이 가장 낮지만(가장 부정적인 정서) 별점이 5인 리뷰:
sample_reviews[(sample_reviews.stars == 5) & (sample_reviews.polarity == -1)].head(10)
그림 7
극성(가장 긍정적인 정서)이 가장 높지만 별점이 1인 리뷰:
sample_reviews[(sample_reviews.stars == 1) & (sample_reviews.polarity == 1)].head(10)
그림 8
두 테이블 모두 이상하게 보입니다. 분명히 일부 극성은 관련 등급과 일치하지 않습니다. 왜 그런 겁니까?
조금 더 파헤친 후 TextBlob은 극성과 주관성을 할당할 수 있는 단어와 구를 찾아 이동하고 Yelp 리뷰와 같은 더 긴 텍스트에 대해 모두 함께 평균을 냅니다.
저는 TextBlob을 사용하여 품사 태깅, 명사구 추출, 분류, 번역 등과 같은 다른 많은 NLP 작업을 수행할 수 있습니다.
참조:
도서: 알고리즘 트레이딩을 위한 실습 머신 러닝
출처: https://towardsdatascience.com/having-fun-with-textblob-7e9eed783d3f
'IT와 과학 > 주식자동매매기술' 카테고리의 다른 글
| 💰 2020년 코로나 때 이거 알았으면 10배 수익! VIX 지수 완벽 가이드 (0) | 2025.03.03 |
|---|---|
| 삼성전자 주가 선행 수준별 인과관계 그래프 (0) | 2025.03.02 |
| 주식 거래와 관련된 다양한 요소(예: 수익 보고서, 경제 지표, 회사 발표, 장기 시장 주기, 투자자 심리, 글로벌 이벤트 등)에 대한 정보를 자동으로 입수하는 방법 (1) | 2025.03.02 |
| 주식 매수 및 매도 타이밍에 영향을 미치는 요인 분석 (1) | 2025.03.02 |
| 상장법인목록 python으로 가져오기 (0) | 2021.01.24 |

